AI-DAPT is pioneering a transformative approach to AI lifecycle management by blending human oversight, hybrid science-guided models, and explainable AI techniques. This blog takes a deep dive into the AI-DAPT platform, drawing from the comprehensive documentation of its reference architecture, workflows, and technical underpinnings.

Core Capabilities Without the Complexity
AI-DAPT provides a robust set of services and components designed to tackle data ingestion, annotation, cleansing, feature engineering, and model experimentation. Rather than overwhelming users with every detail, AI-DAPT integrates these tools into intuitive, API-driven services. The platform supports dynamic data pipelines and incorporates explainability and observability directly into the lifecycle, ensuring transparency and accountability.
Platform Architecture
The AI-DAPT platform is designed as an advanced, multi-layered architecture to efficiently manage the entire data and AI lifecycle. It is structured into eight distinct service layers, each dedicated to specific functions that collectively ensure scalable, secure, and interoperable AI development and deployment.
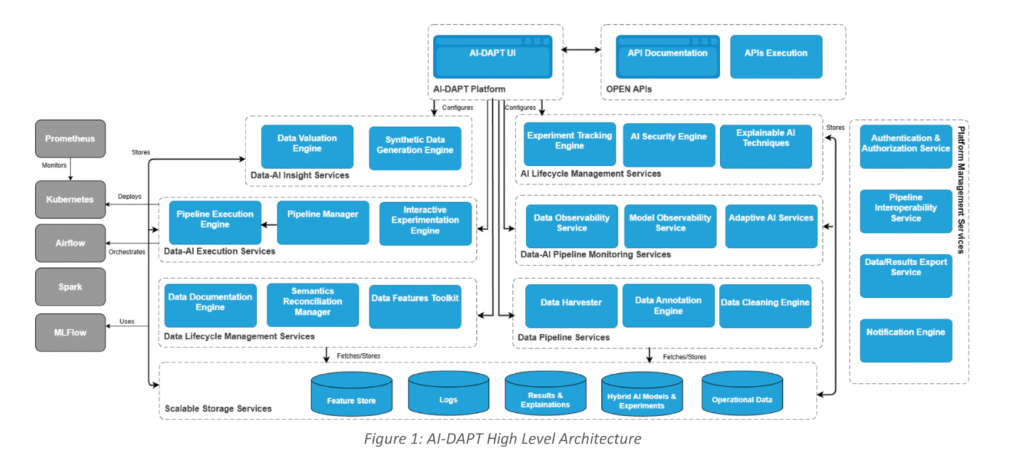
Key Architectural Layers and Their Functions:
- Scalable Storage Services: This foundational layer supports diverse data persistence needs, storing datasets, AI models, pipeline configurations, operational logs, and metadata. It optimizes data discoverability and query performance, leveraging tools like MinIO for distributed object storage and MongoDB for flexible NoSQL data management.
- Data Pipeline Services: These services handle data ingestion and preparation through components such as:
- Data Harvester that fetches the required data at rest (batch files) or data in motion (near real-time data),
- Data Annotation Engine that performs semantic annotations at feature structure level (mapping them to an appropriate data model supported in the Semantics Reconciliation Manager) and any harmonization/transformation that is needed on the feature values,
- Data Cleaning Engine that applies the appropriate user-defined and/or automated ML-based cleaning rules.
- Data Lifecycle Management Services: This layer ensures consistent data management with tools like:
- Data Documentation Engine responsible for extracting and managing metadata at dataset and feature levels,
- Semantics Reconciliation Manager which oversees the lifecycle of cross-domain data models, ensuring integrity, validity, and adaptability to evolving stakeholder needs,
- Data Features Toolkit that helps users with feature engineering during data preparation for AI and analytics. This step tailors features for model training, improving model performance.
- Data-AI Execution Services: Responsible for orchestrating data and AI pipelines, this layer includes:
- Pipeline Execution Engine responsible for executing pipelines while guaranteeing performance requirements. The engine continuously monitors the pipeline performance and execution status, while stores results and metrics in the AI-DAPT Scalable Storage Services. By using the DAG generated by the Pipeline Manger the Pipeline Execution Engine allocates the required resources to run the pipelines within the AI-DAPT platform.
- Interactive Experimentation Engine providing environments for early-stage development and experimentation using computational notebooks,
- Pipeline Manager built to assist in the development, configuration, and management of both data-driven and AI-focused pipelines. It offers a collection of prebuilt data transformation functions and integrates with other AI-DAPT services to improve data processing. Furthermore, it features a catalogue of AI/ML algorithms for model training and deployment.
- Data-AI Insights Services: These services foster collaboration between business experts and data scientists by providing:
- Data Valuation Engine assessing data quality and bias,
- Synthetic Data Generation Engine enabling controlled synthetic data creation using generative AI.
- Data-AI Pipeline Monitoring Services: Ensuring real-time oversight, this layer includes:
- Data Observability Service which monitors data pipeline execution, detects anomalies, and raises alerts.
- Model Observability Service tracking AI model performance over time, identifying drift, and recommending retraining or adaptive AI techniques.
- Adaptive AI Services helps users ensure the robustness and performance of their production models through human-in-the-loop strategies. By integrating model and data observability metrics with user-defined rules, the service generates relevant alerts and recommendations that could trigger model retraining or rebuilding, pending human review and approval.
- AI Lifecycle Management Services: Focused on AI model design and validation, key components are:
- Experiment Tracking Engine enabling users to track, compare, and optimize model training experiments.
- AI Security Engine, which identifies and mitigates potential adversarial attacks on AI models,
- Explainable AI Techniques component which provides a range of methods aimed at improving the understanding of trained hybrid AI models. This feature allows users to gain a clearer view of how the hybrid AI models operate internally.
- Platform Management Services: This essential layer provides security and interoperability through:
- Authentication & Authorization Service for secure access,
- Notification Engine managing user-defined alerts and event notifications,
- Data/Results Export Service facilitating secure extraction and accessibility of requested data,
- Pipeline Interoperability Service, enabling seamless integration with external AI-DAPT compliant solutions.
The platform employs a robust communication framework combining real-time distributed message brokers, REST APIs, and GraphQL queries. This ensures seamless, scalable, and efficient interaction between services and components. It integrates a powerful suite of open-source tools such as Apache Airflow for workflow orchestration, Kafka for real-time data streaming, Apache Spark for large-scale data processing, and MLflow for machine learning lifecycle management.
Workflows within the AI-DAPT Platform
Whether you’re a data scientist, engineer, or business analyst, AI-DAPT offers guided workflows to simplify your experience. Users can ingest and sculpt data, build and track explainable AI pipelines, and extract actionable insights, all while ensuring compliance with fairness, robustness, and privacy standards. Interactive environments like notebooks, drag-and-drop interfaces, and seamless tracking features allow for experimentation without sacrificing governance. Human-in-the-loop interactions help validate decisions, making AI-DAPT not just automated but also trustworthy.
AI-DAPT supports three primary user journeys, each mapped to a specific interaction with the platform and supported by the architecture layers above.
1. Data Ingestion & Sculpting Workflow: From the moment data enters the platform, tools like the Data Harvester, Data Documentation Engine, and Data Cleaning Engine come into play to ensure high-quality, well-documented inputs. This workflow supports both batch and streaming data sources, integrating validation and metadata management. It spans:
- Harvesting from APIs, sensors, or files,
- Annotating and harmonizing data semantics,
- Cleaning data to ensure consistency,
- Documenting metadata and data lineage,
- Feature engineering for model training,
- Storing curated datasets for reuse.
2. XAI Pipeline Workflow: Focused on explainable AI, this journey guides users through the creation and execution of AI pipelines that emphasize transparency. It leverages the Explainable AI Techniques and the Experiment Tracking Engine to ensure that models are interpretable and performance is traceable. It integrates:
- Science-based models and machine learning components,
- Real-time observability and performance tracking,
- Explainability techniques embedded in the workflow.
3. XAI Pipeline Insights and Results Workflow: This journey continues from execution to results, enabling users to derive insights from model outputs. Services like the Data Valuation Engine and Observability Services ensure that data and model behavior remain trustworthy, even post-deployment. The final journey focuses on insight consumption. Business users interact with dashboards and interfaces that:
- Present transparent, traceable AI outcomes,
- Allow for exploration of data valuation, risk, and bias,
- Provide real-time alerts on model drift or data anomalies.
Together, these workflows illustrate the AI-DAPT platform’s commitment to building trust in AI systems through structured, transparent, and iterative processes.
The Road Ahead
AI-DAPT is actively evolving. With its reference architecture as the foundation, the upcoming alpha, beta, and final releases will expand the platform’s capabilities, ensuring it stays aligned with real-world use cases across health, robotics, energy, and manufacturing.