
Towards the beta Release
Building trustworthy AI is not a sprint. It requires the kind of sustained, collaborative effort that only a consortium of committed partners — researchers, engineers, and domain experts — can deliver.
At Month 24, we are proud to announce the Alpha release of the AI-DAPT platform: a working, integrated system that brings together two years of architecture, development, and validation work across eight European partner organizations.
This is not a proof of concept. It is the first release of a real platform.
What AI-DAPT is built to do
AI-DAPT is pioneering a transformative approach to AI lifecycle management by blending human oversight, hybrid science-guided models, and explainable AI techniques.
The problem it addresses is one that many organizations quietly struggle with: AI pipelines that are rigid, opaque, and brittle when conditions change. Data changes. Requirements evolve. Models drift. Most platforms treat these as edge cases. AI-DAPT treats them as the norm.
The platform supports standalone data operations, dynamic data pipelines and incorporates explainability and observability directly into the lifecycle, ensuring transparency and accountability at every step.

What the Alpha includes
The Alpha release brings the full platform architecture (see article “AI-DAPT Platform: Architecting Trustworthy AI with Seamless User Journeys”) to life for the first time, structured into eight distinct service layers that collectively ensure scalable, secure, and interoperable AI development and deployment.
From raw data to curated datasets
The Data Pipeline Services handle the ingestion and preparation of AI-DAPT data assets through several complementary components. The Data Harvester automates the ingestion of raw data at rest or in motion from an organisation’s databases, data lakes, and other source systems, supporting recurring ingestion cycles that keep AI-DAPT datasets aligned with their underlying sources. The Data Valuation Engine then assesses the quality and bias of these assets, helping users ensure the data feeding their AI operations is both reliable and fair.
From there, the Data Annotation Engine applies manual and AI-assisted semantic annotation at both data and feature level, drawing on shared common data models to harmonise assets from heterogeneous sources so they can be jointly interpreted and combined. Underpinning this, the Semantics Reconciliation Manager manages the onboarding and lifecycle of those common data models. The Data Cleaning Engine completes this stage by detecting and remediating data quality issues — such as anomalies and missing values — that would otherwise degrade ML performance, combining user-defined rules with automated, ML-based cleaning techniques across both training and production data.
Once ingested, annotated, and cleaned, datasets are ready for feature engineering. The Data Features Toolkit improves model performance through the engineering of new training features from existing data, offering a palette of techniques — including feature extraction and feature selection — that users can apply individually or in combination.
For cases where real data is insufficient, non-representative, or unusable due to privacy constraints, the Synthetic Data Generation Engine produces customizable synthetic data — built from existing data or generated from scratch — along with utility measures and visualizations to evaluate its quality and representativeness.
Pipelines you can see and control
One of the most visible components in this release is DAVE, the Pipeline Manager. DAVE offers a visual environment where users can design, configure, and execute data and AI pipelines in an intuitive and interactive way. By combining usability with flexibility, it enables both technical and domain experts to actively participate in the development of AI solutions.
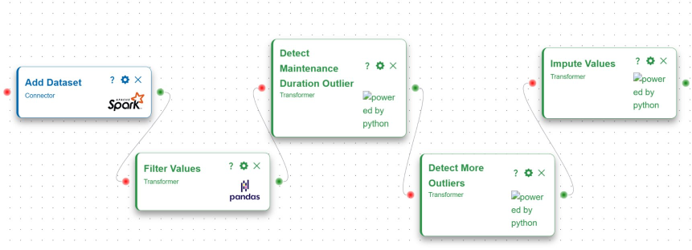
Under the hood, DAVE leverages Apache Airflow for workflow orchestration and MLflow for model lifecycle management. Users can:
- Connect different data sources and processing steps
- Orchestrate complex workflows across the AI lifecycle
- Experiment with different configurations and models
- Monitor and refine pipelines as they evolve over time
Human judgment stays in the loop
Rather than fully automating every step, DAVE allows users to remain actively involved through the concept of operators — internal operators representing automated processing steps, and external operators where human input, validation, or decision-making is required. Domain experts can validate data, adjust model parameters, or approve results before moving to the next stage.
Transparency at every step
After each operator execution, users can inspect intermediate results, understand how data is being transformed, and quickly identify anomalies or unexpected behaviours. This step-by-step visibility turns pipelines into transparent processes rather than black boxes, enabling teams to debug workflows, validate transformations, and assess the impact of each processing step.
Security and access governance
The platform includes an Authentication and Authorization Service and an AI Security Engine that identifies and mitigates potential adversarial attacks on AI models. Data governance is built into the pipeline from the start, not added as an afterthought.
Hybrid AI: science and machine learning, combined
Many AI systems are built purely on data, yet most real-world problems are governed by well-understood physical laws. AI-DAPT addresses this through hybrid AI models, which combine domain knowledge — physical equations, conservation laws, expert rules — with data-driven machine learning. The result is predictions that respect known constraints, perform better in data-scarce or noisy settings, and are more interpretable than black-box approaches.
The primary mechanism is residual learning: a simulator generates a baseline prediction, and a machine learning model learns to correct the gap between that prediction and real-world observations. Scientific knowledge is preserved, not discarded. This is complemented by approaches such as Physics-Informed Neural Networks (PINNs), where governing equations are directly embedded in the model training process.
The Hybrid Model Engineering Engine brings this capability into the platform through DAVE’s graphical interface, offering a catalog of model templates, configurable training parameters, and interfaces to integrate custom simulators. Trained models are automatically tracked and stored for reuse across pipelines.
What comes next
With its reference architecture as the foundation, the upcoming beta and final releases will expand the platform’s capabilities, ensuring it stays aligned with real-world use cases across health, robotics, energy, and manufacturing.
In the near term: broader demonstrator scenarios, hardened governance, open API documentation, and an expanded component series on this blog — starting with the recently published deep-dive on DAVE.
Follow along
The best way to stay close to the project is through ai-dapt.eu and our channels on LinkedIn and X. Technical documentation and the component blog series will grow through the second half of 2026.
The Alpha is live. The platform is real. The work continues.